Dziedzic
I am a Tenure Track Faculty Member at CISPA, where I co-lead the SprintML group with a research focus on Secure, Private, Robust, INterpretable, and Trustworthy Machine Learning. We design robust and reliable machine learning methods for training and inference of ML models while preserving data privacy and model confidentiality.
Befor joining CISPA, I was a Postdoctoral Fellow at the Vector Institute and the University of Toronto, a member of the CleverHans Lab, advised by Prof. Nicolas Papernot. I earned my PhD in computer science at the University of Chicago, where I was advised by Prof. Sanjay Krishnan and worked on input and model compression for adaptive and robust neural networks. I obtained my Bachelor's and Master's degrees in computer science from Warsaw University of Technology in Poland. I was also studying at DTU (Technical University of Denmark) and carried out research at EPFL, Switzerland. I also worked at CERN (Geneva, Switzerland), Barclays Investment Bank in London (UK), Microsoft Research (Redmond, USA) and Google (Madison, USA).
European Championship: I am a founding organizer of the CISPA European Cybersecurity and AI Hackathon Championship. This bold initiative invests in the next generation of researchers by promoting cybersecurity skills, fostering interest in AI, and raising awareness of the need for trustworthy technologies. Through a Europe-wide series of regional competitions in France, Austria, Sweden, Spain, and Poland, the Championship brings together young talent from across the continent to develop the skills and capacities needed to address our grand challenges in cybersecurity and AI.
Hiring: We are searching for ambitious students who would like to work with us in our SprintML group at CISPA. Please, feel free to email me if you are interested in this opportunity.
Email: adam.dziedzic@sprintml.com (my public PGP key)
Address: CISPA Helmholtz Center for Information Security, Stuhlsatzenhaus 5, 66123 Saarbrücken, Germany
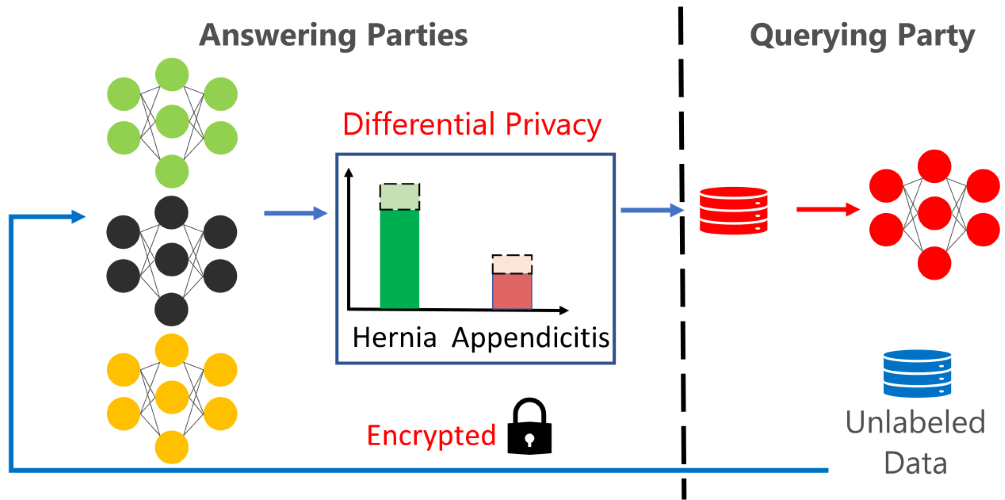
 paper
paper slides
slides talk
talk bibtex
bibtex